

Can I Make Money Knowing Only Python
Make Money With Python — The Sports Arbitrage Projection
Full code to make extra money with sports arbitrage.
So you've finally finished a course that teaches yous the basics of Python; you lot've learned how lists, dictionaries, loops and conditionals work but you nevertheless tin't make money with your Python skills. I've been in this situation after i year of learning Python; fortunately, y'all can brand extra money with some noesis of Python, Selenium and sports arbitrage.
Sports arbitrage or surebets is the do of taking advantage of bookmakers' errors when calculating odds for the same sports event. When this happens, you tin can make a turn a profit regardless of the result by placing one bet per each outcome with different bookmakers.
In this tutorial, I'll guide you through the full code you need to scrape live betting data from 3 betting sites, which volition detect surebets for united states of america. There are ii types of surebets: pre-match and live surebet. We'll focus on alive surebets because it's the most assisting merely a bit difficult to scrape since the data is 'dynamic.'
The tutorial would exist split into 4 sections:
- Scraping alive betting information with Selenium: In Selenium, we'll use
WebdriverWait,Expected Weather(EC)andSelect. As well, we'll customize the chromedriver's default options to scrape in the background. Some Python's essentials we need aretry-exceptblock and lists. - Make clean and transform live odds information: Odds data from different bookmakers come in different forms, so we need to format them properly to exist able to compare them and find surebets. The Pandas library comes in handy for this.
- Matching team names: Bookmakers vary the mode they write the same team names. Some may write New York Metropolis FC, while others would just refer to it equally NYC FC, so nosotros demand to exercise some cord matching showtime. We'll use Fuzzywuzzy for this.
- Finding surebets and calculating the stakes: We'll create Python functions that find surebets, calculates the stakes for us and tell united states of america the potential profit.
You have nothing to worry near if you never used advanced tools on Selenium or libraries such as Pandas or Fuzzywuzzy earlier. I'll explain how they work pace past step when nosotros demand them.
Notwithstanding, some basics on Selenium would be necessary to follow this tutorial; otherwise, the explanation would exist as well long. I made some other tutorial where I explained the very basics of Web Scraping with pre-match surebets as an case. The tutorial tin be found in the link below and a web scraping cheat sheet I created tin be constitute on this link.
Also, before we start coding, make certain you're completely familiarized with the concept of surebets, then the code we're near to write makes sense to you.
Notation : I built a assisting betting tool with Python's Selenium and Pandas. In the article below I show the total code and explain how I did it.
Legal disclaimer: Massive scraping of websites causes high traffic and could burden them. If you are accessing websites, yous should always consider their terms of service and check the 'robots.txt' file to know how the site should be crawled. Moreover, I do non promote gambling, no matter what kind of betting it is.
Time to Code
Amidst the three betting sites, I considered this i the hardest one to become information from, so one time you're able to get alive odds from this one, you'd be able to understand the code for the other two sites easily and also create your own betting site scraper.
Let'due south start coding! The total code is bachelor at the end of section 4.
In example you lot already followed this tutorial and suddenly the code stopped working, below you can detect some updates I made to the lawmaking because of some changes fabricated to the website.
Update March 21st, 2021:
- I uploaded CSV output examples of the Tipico, Betfair, and Bwin scrapers to my Github , and so you have an idea of how the output of section 1 (Scraping live betting data with Selenium) looks like. Withal, this data still needs to exist preprocessed in sections 2 and three before finding surebets.
- There was a slight alter of names in the dropdowns of the Tipico betting site. Initially, the name was, "Both teams to score?" only at present it is "Both Teams to Score" The code beneath considers the new names.
Update Apr 22nd, 2021: (simply Tipico website)
- Evidently, it's not possible to access the website from some countries. If that's the case apply a VPN and connect to some country in Europe (TunnelBear works adept for me and it'south free)
- The website made some major changes to the live section. Now the prematch and live department it's inside one container named "Program_UPCOMING" so to continue the scraper working, I had to remove and add some lines of code that I specified in the total lawmaking bachelor at the cease of the article as well as in the snippets below.
- It seems the website now works with some feature that doesn't permit all events to show upward in the live section (unless you lot scroll all the way downwardly) If y'all see that not all the events were scrapped, employ the code beneath to whorl all the way downwardly and scrape all the events. (I'grand including this only in the full code, in example y'all need it)
#roll down to the lesser to load all matches
commuter.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(three) #implicit wait to let the page load all the matches 4. I updated the website URL to scrape, then now information technology goes straight to the "football game" section (it helps to simplify the code)
If the code stops working, permit me know in the comments!
Tabular array of Contents
1. Scraping live betting data with Selenium
- Importing libraries
- Irresolute Chromedriver default options
- Select values from dropdown menus
- Looking for 'alive events' and 'sports titles'
- Scheme for scraping live games
- Observe 'empty events'
- Remove empty_events from single_row_events
- Getting live odds
2. Clean and transform live odds data with Pandas
3. String matching with Fuzzywuzzy
four. Observe surebets and calculate stakes
- Find surebets
- Summate the stakes
- Last Stride: Automate the Python Script
five. Full Code of three Bookmakers
6. Final Note ane. Scraping live betting data with Selenium
Importing libraries
We need to import Optionsto change chromedriver's default options; Select for selecting within dropdown menus andBy, WebDriverWait, EC,timeto expect for a certain condition to occur.
Irresolute Chromedriver default options
To go on scraping while doing something else on the figurer, we need to use the headless mode. To exercise so, we write the following code:
Breaking down the code:
-
options = Options()creates an case of the Options grade -
options.headless = Trueturns on the headless mode -
options.add_argument('window-size=1920x1080')opens the windows in a customized size on the groundwork -
webdriver.Chrome(path, options = options)applies the changes nosotros made in the chromedriver -
commuter.goopens the browser -
webrepresents the betting site's URL, whilepathrepresents the chromedriver'south path in your calculator
If you don't want to piece of work in headless mode, then write choice.headless=Faux and use driver.maximize_window() instead of options.add_argument('window-size=1920x1080') as shown in the full code.
Select values from dropdown menus
We need to select the betting markets we want to get data from. We exercise this with Select and the Xpath of the dropdown. To become the Xpath, do this:
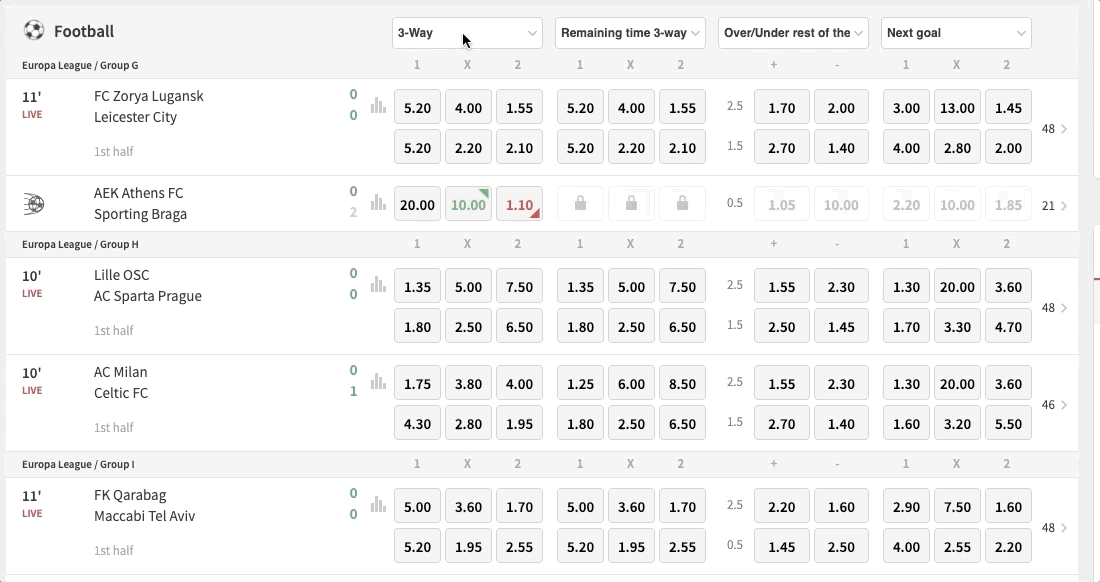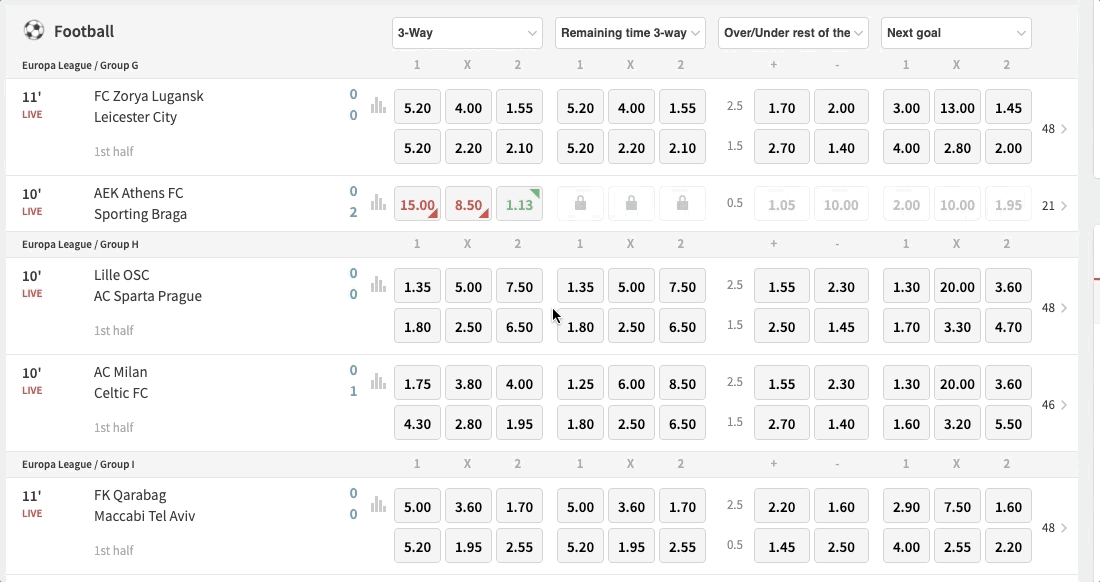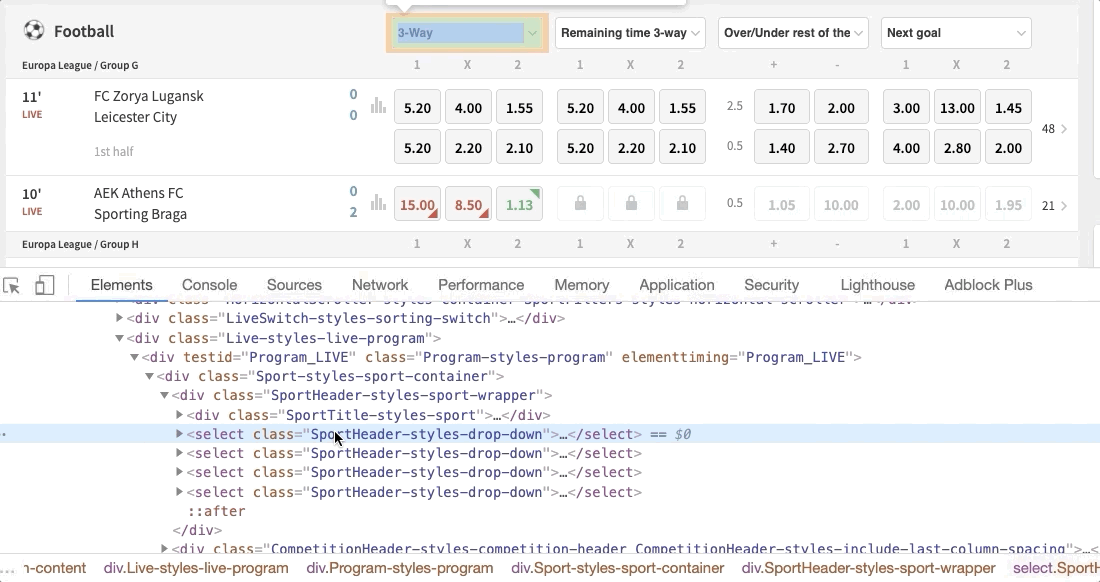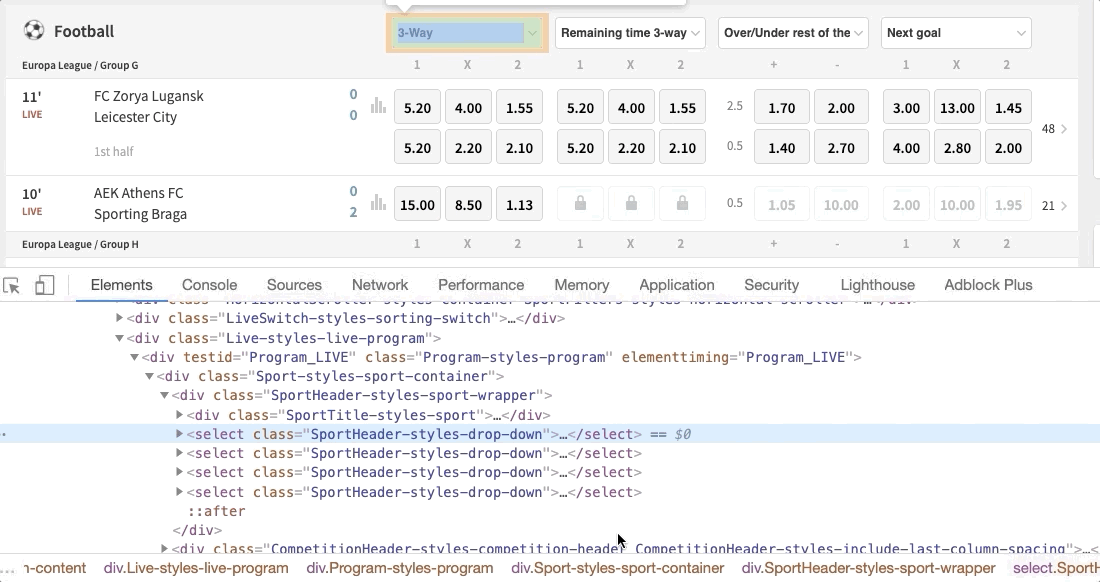
But offset, keep in listen that every fourth dimension you lot open some betting sites, a cookies imprint is displayed. We need to get rid of them by clicking the 'take button.'
To click on the 'accept button' and so select on the dropdown menus, we write the following code:
Breaking downwardly the code:
-
WebDriverWait(commuter, 5).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="_evidon-accept-push button"]')))makes the driver wait until the 'ok button' of the cookie imprint is clickable. If this throws an mistake, and so use 'option 2' instead. To go the Xpath, correct-click on the 'ok button' and inspect as we did before for the dropdown menu. -
WebDriverWait(driver,five).until(EC.presence_of_all_elements_located((By.CLASS_NAME, '...')))makes the driver wait some seconds until the dropdown menus are located -
Select('...')selectsdropdownsmenus -
first_dropdowni of the three dropdowns that contain betting markets -
first_dropdown.select_by_visible_text()selects an element inside the dropdown menu with the help of the betting market's name.
I'chiliad choosing 'Both Teams to score' and 'Over/Nether' in detail considering they represent betting markets that I consider piece of cake to discover surebets.
Looking for 'alive events' and 'sports titles'
Before getting the data, we need kickoff to look for live events. Also, to simplify the analysis, we'll choose only 'football game' in sports' names. To do and then, nosotros write the post-obit code:
Breaking down the code:
-
boxrepresents the box that contains sports events. The site likewise contains upcoming events, which we don't need for this analysis. -
commuter.find_element_by_xpath()helps usa find an chemical element within the website through the 'Xpath' of that chemical element.
Different Xpaths from most elements we worked with earlier, the 'live events' element is trickier to get. For that reason, we need to be very specific. And so we apply the contains pick to match an element that contains Program_LIVE inside thetestid inside a div tag. Check the picture below to detect Program_UPCOMING (Program_LIVE doesn't prove upward anymore after the changes made in the website)
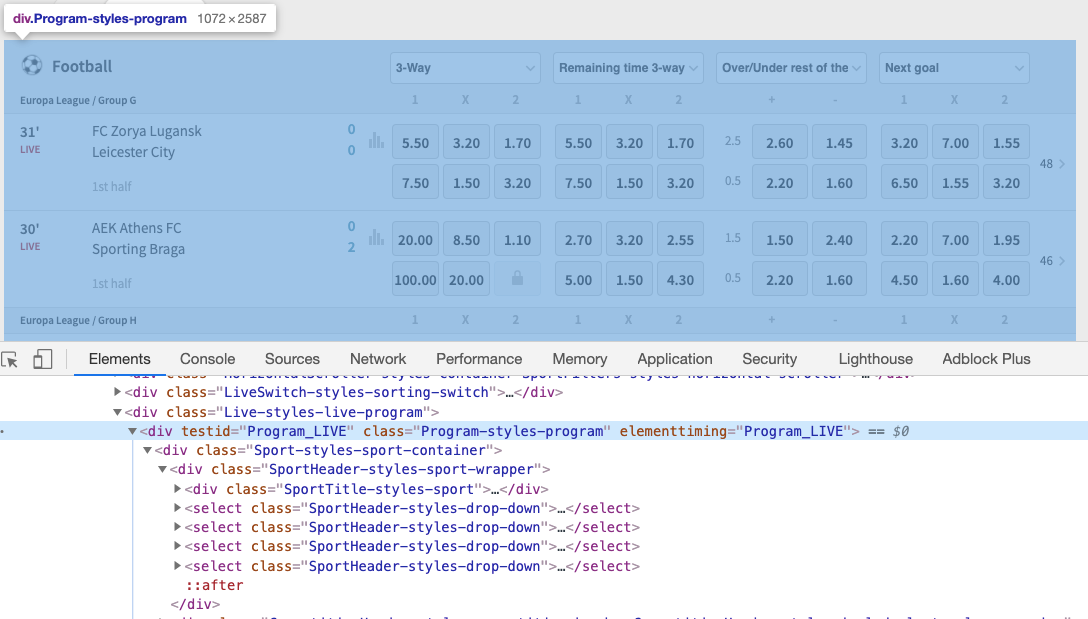
-
sport_titlerepresents the sport name of each department. -
driver.find_element_by_class_name()helps us find an element within the website through the 'class_name' of that element. To obtain the class name, simply follow the aforementioned steps nosotros used before for dropdown menus, merely in this case, click on the 'Football game' header and copy the class name'SportTitle-styles-sport'.
Before nosotros keep with the code, we need to understand the scheme that will help us scrape live data.
Scheme for scraping live games
The scheme for scraping alive games is similar to the ane used for scraping pre-match games. However, live games in the betting site Tipico include 'double row events' and 'empty events' that nosotros need to exclude.
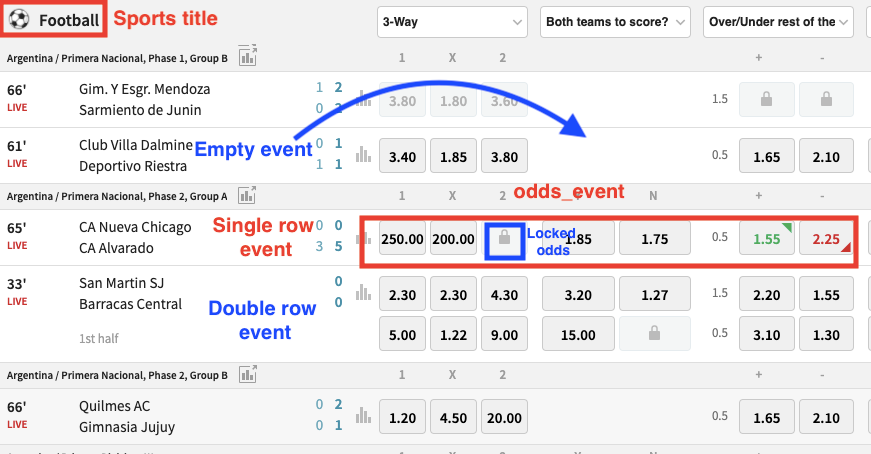
- Sports title: Represents the sports section. The website has many sports available, but nosotros'll focus only on football since it's the most popular sport.
- Double-row issue: Football live events in the first half (0'-45') take 2 rows. The first row contains odds for the full game and the second contains odds for just the first one-half. Nosotros'll merely work with the first row.
- Single-row consequence: Football game live events in the 2nd half (45'-90') take simply 1 row that contains odds for the rest of the game.
- odds_event: Represents the odds available within a row. Each row has i 'odds_event' and each 'odds_event' has 3 boxes with the markets '3-fashion,' 'Over/Under' and 'Handicap' by default.
- Empty events: Live odds might exist suspended for a couple of seconds because of many reasons. We won't consider rows with empty events to simplify the analysis.
Detect 'empty events'
Unlike pre-match games, odds in live games change chop-chop and could be suspended for a couple of seconds at any time. When betting odds are momentarily suspended, the odds are either locked or empty. Locked odds are easy to scrape, merely empty odds are harder. That'southward why nosotros need to locate those empty odds with the post-obit code:
Breaking down the code:
-
for sport in sport_titleloops through the sports listing previously obtained (update: it's not necessary anymore) -
parentrepresents the 'parent node' of thesportchemical element, whilegrandparentis its 'grandparent node' that represents the whole 'football' container inside live events (update: now nosotros have to practise this 3 times to go to the desired node as shown in the code) -
empty_groupsrepresents each football game game with suspended or empty odds -
granparent.find_elements_by_class_name()gives a listing of all the empty odds with class name 'EventOddGroup-styles-empty-group' inside the football live section. You can get the class name by doing this:
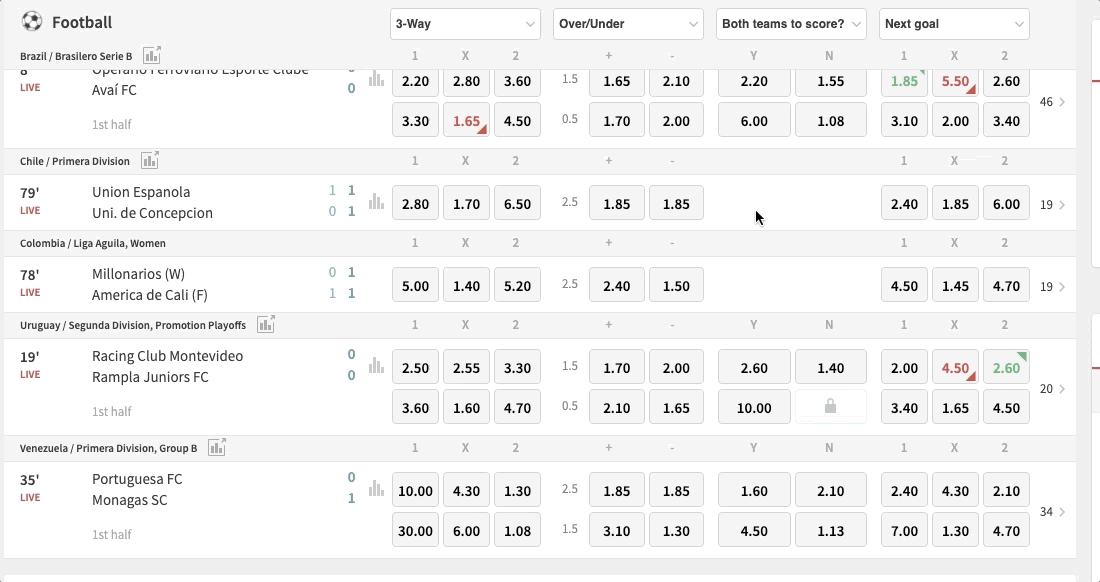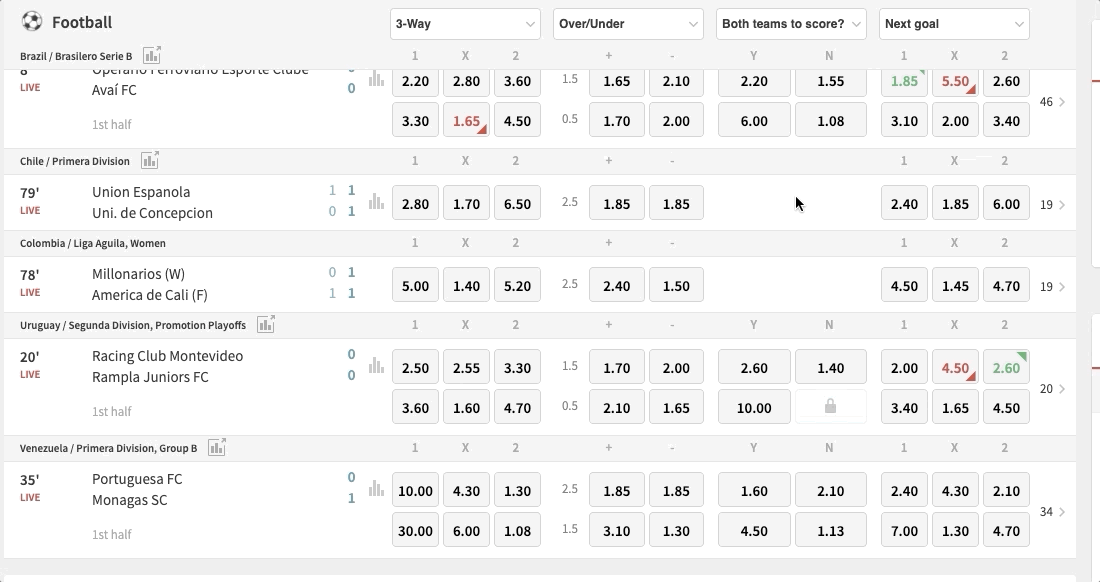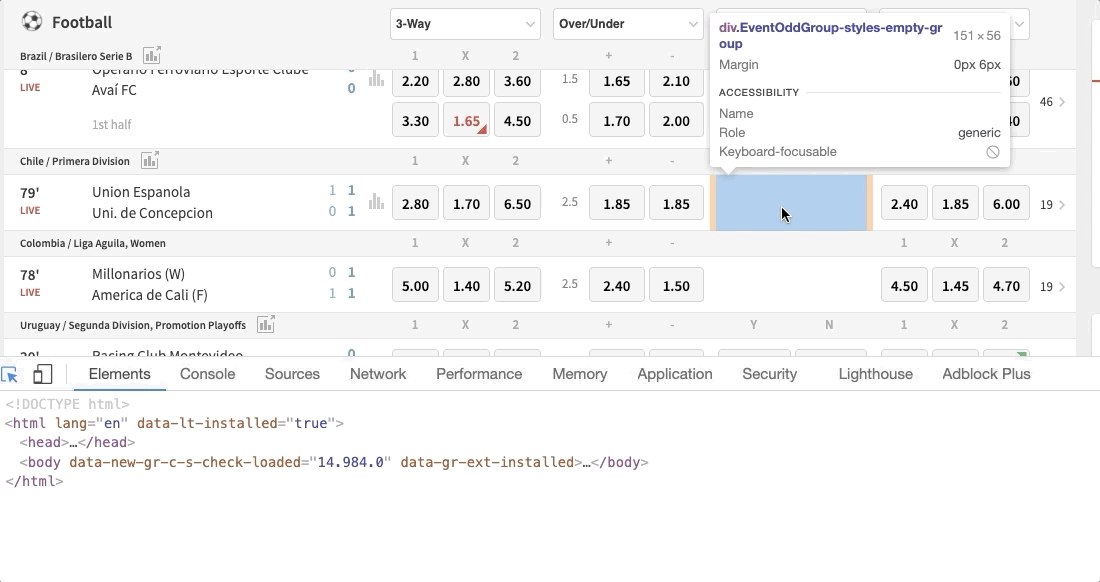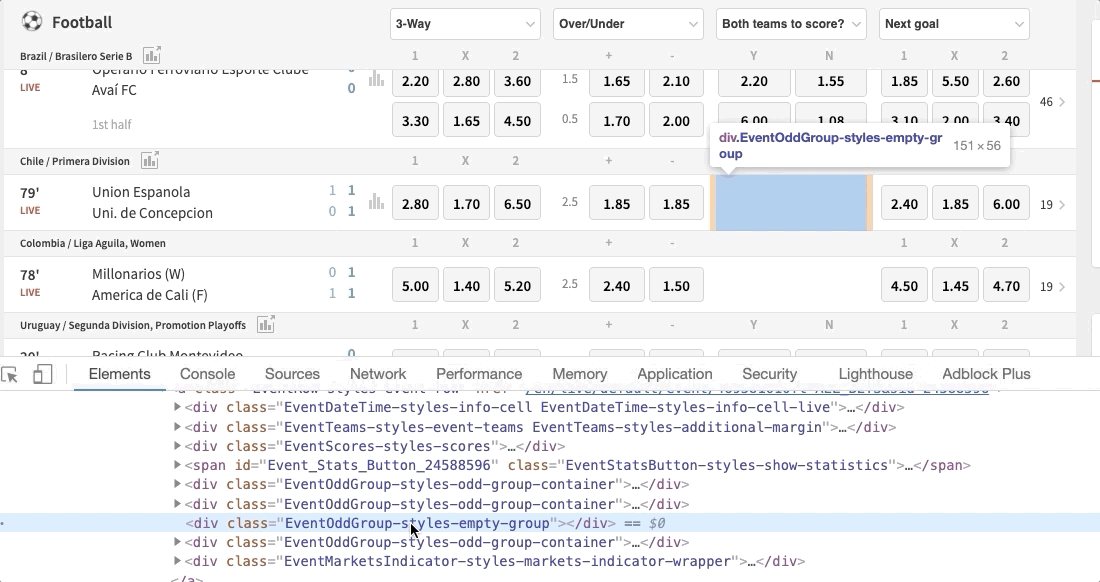
-
empty_eventsrepresents each row or football game game with at to the lowest degree 1 empty odds market (3-fashion, over/under, etc.) -
[empty_group.find_element_by_xpath('./..') for empty_group in empty_groups]is a list comprehension that loops through theempty_groupslist to obtain the 'parent node' of each element, that is, theempty_events -
excepthandles errors that could be encountered in theattemptcake. We need this to handle errors when at that place isn't whatsoever game with empty odds
Remove empty_events from single_row_events
We detect unmarried row events and remove all empty events inside with the following lawmaking:
Breaking downward the code:
-
single_row_eventscorrespond the first row of double-row events or the unique row of single-row events. As we explained before, both represent odds for the full game and we focus on them because it's more than common to find surebets in odds calculated for the whole game. Find the class name of unmarried-row events by inspecting whatever single row. Yous should find this class name'EventRow-styles-consequence-row' -
[single_row_event for single_row_event in single_row_events if single_row_event not in empty_events]list comprehension that excludes any empty games inside thesingle_row_events -
try/excepthandles errors that could exist raised when at that place isn't any game with empty odds
Getting live odds
Each dropdown selected before will give odds for three markets that are extracted with the following code:
Breaking down the code:
-
for match in single_row_eventsloops through all the matches inside the'single_row_events'list -
odd_eventsrepresent each event with odds available -
friction match.find_elements_by_class_name('EventOddGroup-styles-odd-groups')helps us detect all the 'odds_event' inside every friction match. To find the form proper noun'EventOddGroup-styles-odd-groups'just right-click and audit the lawmaking behind 'odds box' as we did before for empty odds -
for team in friction match.find_elements_by_class_name('EventTeams-styles-titles')loops through the elements with the class proper noun'EventTeams-styles-titles'within the 'match' node. Matches have ii teams (home and away team); that's why nosotros demand to loop through them and obtain their name withteam.text.Then they're stored with theappendmethod in theteamslist -
for odd_event in odds_eventsloops over the full number of live matches on the betting site. -
for n, box in enumerate(odds_events)loops through all 'odds boxes' inside a match. In the start, we changed the dropdowns to '3-mode,' 'Over/Under' and 'Both Teams to Score,' and so they're the odds we'll scrape -
rows = box.find_elements_by_xpath('.//*')gives all the children nodes (odds) inside the box element. -
due north==0ways 'only take values from the first box.' In this case, the first box is the '3-mode' box and is stored in thex12list -
rows[0]tells Python 'merely pick the offset row on each odds box.' With this, we ignored the 2d row in double-row events.
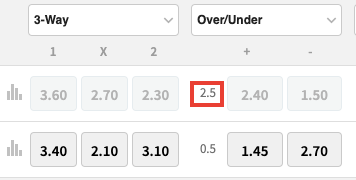
The same process is followed for n==1(Over/Under) and n==2(BTTS), merely in northward==1 we also need to shop the 'goals line.' This represents the total number of goals that you need to win the bet.
For instance, Over 2.5 goals hateful at least 3 goals to win the bet. Permit's suspension down the code for n==1.
-
box.find_element_by_xpath('./..')gives the 'parent node' of the box element that contains the odds. -
goals = parent.find_element_by_class_name('EventOddGroup-styles-fixed-param-text').textfinds the goal line by giving its class proper name. Just right click and inspect the goal line (shown in the pic above) to obtain its class name. Then nosotros obtain the information with.text -
over_under.append(goals+'\n'+rows[0].text)appends the goals line data in a standard format. The over/under odds format will await like thistwo.v\n2.4\n1.v -
driver.quit()closes the Chrome browser
At this point, the scraping part is washed! Now we have to make the information readable and do some pre-cleaning with Pandas. Then we'll save the information with Pickle.
Breaking downwards the lawmaking:
-
dict_gamblingis the lexicon that stores all the lists that contain the odds scraped -
pd.DataFrame.from_dict(dict_gambling)turn the dictionary into a dataframedf_tipico,then we can read it and work with it easily -
df_tipico.applymap(lambda x: ten.strip() if isinstance(ten, str) else 10)cleans all the leading and abaft white spaces that the odds might have with thestripmethod. -
open('...', 'wb')opens a file nameddf_tipicoin the manner 'write bytes' (wb). Nosotros save this in the variableoutput -
pickle.dump(df_tipico, output)saves the dataframe created in the file nameddf_tipico.We used the same proper noun for both the file and the dataframe, but they could be named differently -
output.close()closes the file
Great! We finished scraping the first bookmaker. Bookmaker 2 and three are easier to scrape. The full code of bookmakers ane, 2 and 3 is at the end of this commodity.
Now let'south work with the data obtained to find a surebet automatically!
Role two,3 and 4
From now on, we'll start with another .py file to collect and work with the betting data scraped from bookmaker 1, 2 and 3. In this file, we'll import the following libraries.
Subprocess lets us run scripts in parallel; that is, we can scrape bookmaker one, 2 and 3 at the same time. Pickle lets us load the data scrape in each bookmaker; Pandas help us clean and transform that data and FuzzyWuzzy matches strings needed for squad names.
Although we scraped unlike betting markets, to brand things unproblematic, we'll focus only on the market place 'Both Teams to Score' (BTTS). You can follow along with any other market if you desire. The process is similar.
two. Clean and transform alive odds data with Pandas
As we mentioned before, suspended odds are either locked or empty. When they're locked, empty values like '' are scraped, which is dissimilar from empty odds that give NO values at all and alters other data scaped (that's why we removed it before)
BTTS have two possible outcomes, and so odds look something like this 1.8\n1.7.For that reason, we need to format every locked odds '' as regular odds with no values'0\n0'.
On the other mitt, one time in a while, the odds for one outcome are huge, while the other is so tiny that it might not show up at all. They look something like thistwoscore\n which is the equivalent of 40\n1.01Nosotros'll never find surebets in that scenario, then nosotros need to turn them again into '0\n0' We exercise this with the following code:
Breaking down the code:
-
pickle.load(open up('df_tipico','rb'))loads the dataframedf_tipicocreated in role 1 -
df_tipico[['Teams', 'btts']]selects the 2 columns we'll focus on for this assay -
df_tipico.replace(r'', '0\n0', regex=True)turns locked odds into'0\n0' -
df_tipico.replace(r'^\d+\.\d+$', '0\n0', regex=Truthful)turns huge odds similar40\due northinto'0\n0'.We use regular expressions to grab the design of these odds.
We give the same format for the data inside the 3 dataframes.
3. String matching with Fuzzywuzzy
Bookmakers oftentimes disagree about team names. To lucifer team names that look similar, we use Fuzzywuzzy. This gives a score between ane and 100 that tell us how similar are ii names.
I'll use 60 equally the minimum score needed to consider ii names are the same. However, sometimes this still might match unlike teams. In one case a surebet is plant, use your common sense to see if the teams are actually the same.
After matching strings, we merge dataframes, so we later look for surebets.
Breaking downward the code:
-
df_tipico['Teams'].tolist()turns an assortment into a list calledteams_1 -
process.extractOne(x, teams_2, scorer=fuzz.token_set_ratiocompares the team namexwith a listing with namesteams_2and gives two outputs: the name insideteams_2that is the most similar to the team name10and its score -
df_tipico['Teams'].apply(lambda x:process.extractOne(x, teams_2, scorer=fuzz.token_set_ratio))applies the previous formula to each row of the arraydf_tipico['Teams'] -
.use(pd.Series)transforms the 2 outputs into a data frame that are assigned to the columnsdf_tipico[['Teams_matched_bwin', 'Score_bwin']] -
pd.merge(df_tipico, df_bwin, left_on='Teams_matched_bwin', right_on='Teams')merges 2 dataframes using teams names equally central - df_surebet[df_surebet['Score_bwin']>lx] filters out scores less than 60
-
df_surebet[['Teams_x', 'btts_x', 'Teams_y', 'btts_y']]selects specific columns that we'll use later
The string matching is the same for the three bookmakers. We need to grade pairs to find surebets later. The pairs are bookie1-bookie2, bookie1-bookie3 and bookie2-bookie3.
four. Find surebets and summate stakes
To notice surebets and calculate the stakes, we'll use 2 formulas. The formulas are shown below. If you'd like to know how I came upwardly with those formulas, check this article.
Observe surebets
Breaking downward the formula find_surebets:
-
frame[['btts_x_1', 'btts_x_2']] = frame['btts_x'].apply(lambda x: x.separate('\n')).employ(pd.Series).astype(float)splits the odds into 2 elements. The first is stored in the cavalcade 'btts_x_1'and the second in 'btts_x_2'.Both columns are existence created every bit nosotros apply the formula -
(1 / frame['btts_x_1']) + (1 / frame['btts_y_2'])is the formula to notice surebets. You can also observe surebets in the pair of oddsbtts_x_2andbtts_y_1 -
frame[(frame['sure_btts1'] < i) | (frame['sure_btts2'] < 1)]selects just matches that had results less than i, which is a requirement for a surebet. The'|'symbol is an 'or' conditional. -
frame.reset_index(drop=True, inplace=True)resets the index. We need this to identify the matches in which the lawmaking establish a surebet.
After doing this, we apply the formula to the dataframe of each bookie with find_surebet('...'). Finally, the frames are stored inside the lexicon dict_surebet.
Calculate the stakes
We'll employ the formula beat_bookiesto each element of the dictionary dict_surebet .Nosotros do this to find the stakes necessary for the bet and the profits we'll brand.
Breaking down the lawmaking:
-
total_stakeis the total amount you lot're willing to bet in each game. Y'all have to define the amount advisable for y'all. In this case, I chose 100 -
for frame in dict_surebetloops through the frames of all the bookies we scraped -
if len(dict_surebet[frame])>=1:filters out frames where there wasn't establish any surebet -
for i, value in enumerate(dict_surebet[frame]['sure_btts1']):loops through each row of the column 'sure_btts1'within the dataframe.enumerategives ii outputs: the number of iterationiand thevalueof the row. We need theito identify the odds and team name where the surebet was plant (iis the equivalent of the dataframe'southward index) -
if value<1filters out not-surebets inside'sure_btts1'or'sure_btts2' -
odds1 =bladder(dict_surebet[frame].at[i, 'btts_x'].divide('\due north')[0])finds the first odds with the assistance of the.atmethod and the indexi. Since odds come up in pairs, we take to split them and selection the one we desire through[0]or[1].Subsequently that, we make sure the effect obtained is a number withbladder -
teams = dict_surebet[frame].at[i, 'Teams_x'].split('\northward')finds the squad names through the.atmethod and the alphabetizei. We don't need the'\n'when we print the team names, and so nosotros get rid of them withsplit -
dict_1 = beat_bookies(odds1, odds2, total_stake)applies the formulabeat_bookiesto the surebet we found. The formula returns a lexicon -
print(str(i)+' '+'-'.join(teams)+ ' ----> '+ ' '.join('{}:{}'.format(x, y) for x,y in dict_1.items()))prints all the data necessary to make a turn a profit regardless of the effect. The.particular()unpacks the element within the dictionary created. We loop through the elements and print them in a specific format
Finally, y'all tin can add this code, at the beginning of the file that nosotros started working from Function ii, to scrape the 3 bookies at the same time:
subprocess.run("python3 bookie1_tipico_live.py & python3 bookie2_bwin_live.py & python3 bookie3_betfair_live.py & expect", shell=Truthful) This final code works on Mac. All the same, information technology seems there'south an event with Windows. Permit me know if it worked for you lot on Windows.
Congratulation! Now you're able to find surebets in any bookie! Beneath yous accept a tutorial on how to automate this script and also the full code of the 2 files we worked on (code bookie 1 + code from Part2,3,4) plus the full code of bookmaker 2 and bookmaker 3.
Final Step: Automate the Python Script
The terminal stride of this tutorial is to automate the Python script, and then you can run it daily, weekly or at specific times. Here'due south a tutorial on how to automate Python scripts on Mac and Windows in three simple steps.
If you'd like to scrape websites without getting blocked, check this article:
Full Code of 3 Bookmakers
Before you run the code, please make sure you read the notes below.
Bookie 1
Notes:
- Switch betwixt option 1 or 2 in case in that location's a problem clicking the cookies banner.
Bookie two
Bookie 3
Notes:
- Switch between pick ane or 2 in case in that location's a trouble clicking the cookies banner.
- Below the comment 'choose whatever market,' write the markets exactly as shown in your browser. The name of the marketplace may change because of your browser'southward linguistic communication. Only type the name of the market equally shown in your browser or re-create it past inspecting the element.
- In line 66, you have to discover how 'suspended odds' is written in the betting site's language. Change the word 'Suspedido' to the equivalent in your browser's language.
Would you like to know more than about how to beat the bookies? If so, cheque this article I wrote:
Finding and calculating surebets among bookies 1,2 and 3
Note:
- Line 12
'subprocess'runs more one procedure in parallel on Mac. Verify if it works on Windows.
Last Notation
Now y'all're able to find surebets in three bookmakers. It'due south been a long tutorial, but completely worth it! Let me know if something explained isn't clear. I'll exist happy to clarify any concept.
Source: https://medium.datadriveninvestor.com/make-money-with-python-the-sports-arbitrage-project-3b09d81a0098
Posted by: pelhamminver.blogspot.com
0 Response to "Can I Make Money Knowing Only Python"
Post a Comment